Ich werde einfach versuchen, die vorherige Antwort umzuschreiben, mit mehr Details, warum sie optimal ist.
Der A*-Algorithmus stammt direkt aus wikipedia est
function A*(start,goal)
closedset := the empty set // The set of nodes already evaluated.
openset := set containing the initial node // The set of tentative nodes to be evaluated.
came_from := the empty map // The map of navigated nodes.
g_score[start] := 0 // Distance from start along optimal path.
h_score[start] := heuristic_estimate_of_distance(start, goal)
f_score[start] := h_score[start] // Estimated total distance from start to goal through y.
while openset is not empty
x := the node in openset having the lowest f_score[] value
if x = goal
return reconstruct_path(came_from, came_from[goal])
remove x from openset
add x to closedset
foreach y in neighbor_nodes(x)
if y in closedset
continue
tentative_g_score := g_score[x] + dist_between(x,y)
if y not in openset
add y to openset
tentative_is_better := true
elseif tentative_g_score < g_score[y]
tentative_is_better := true
else
tentative_is_better := false
if tentative_is_better = true
came_from[y] := x
g_score[y] := tentative_g_score
h_score[y] := heuristic_estimate_of_distance(y, goal)
f_score[y] := g_score[y] + h_score[y]
return failure
function reconstruct_path(came_from, current_node)
if came_from[current_node] is set
p = reconstruct_path(came_from, came_from[current_node])
return (p + current_node)
else
return current_node
Lassen Sie mich also alle Einzelheiten aufzählen.
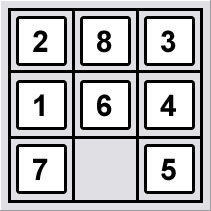
heuristic_estimate_of_distance ist die Funktion Σ d(x i ), wobei d(.) der Manhattan-Abstand der einzelnen Quadrate x i aus seinem Zielzustand.
Also die Einrichtung
1 2 3
4 7 6
8 5
hätte eine heuristic_estimate_of_distance von 1+2+1=4, da 8,5 jeweils 1 von ihrer Zielposition mit d(.)=1 entfernt sind und 7 2 von ihrem Zielzustand mit d(7)=2 entfernt ist.
Die Menge der Knoten, die A* durchsucht, ist definiert als die Ausgangsposition, gefolgt von allen möglichen legalen Positionen. Das heißt, die Ausgangsposition x ist wie oben:
x =
1 2 3
4 7 6
8 5
dann die Funktion neighbor_nodes(x) ergibt die 2 möglichen legalen Züge:
1 2 3
4 7
8 5 6
or
1 2 3
4 7 6
8 5
Die Funktion dist_between(x,y) ist definiert als die Anzahl der Quadratzüge, die für den Übergang vom Zustand x a y . Für die Zwecke Ihres Algorithmus wird dies in der Regel immer gleich 1 in A* sein.
closedset y openset sind beide spezifisch für den A*-Algorithmus und können unter Verwendung von Standarddatenstrukturen (Prioritätswarteschlangen, glaube ich) implementiert werden. came_from ist eine Datenstruktur, die verwendet wird, um die Lösung zu rekonstruieren, die mit der Funktion reconstruct_path dessen Daten auf Wikipedia zu finden sind. Wenn Sie sich die Lösung nicht merken wollen, brauchen Sie dies nicht zu tun.
Zuletzt möchte ich noch auf die Frage der Optimalität eingehen. Betrachten Sie den Auszug aus dem A*-Wikipedia-Artikel:
"Wenn die heuristische Funktion h zulässig ist, was bedeutet, dass sie die tatsächlichen minimalen Kosten für das Erreichen des Ziels nie überschätzt, dann ist A* selbst zulässig (oder optimal), wenn wir keine geschlossene Menge verwenden. Wenn eine geschlossene Menge verwendet wird, muss h auch monoton (oder konsistent) sein, damit A* optimal ist. Das bedeutet, dass für jedes Paar benachbarter Knoten x und y, wobei d(x,y) die Länge der Kante zwischen ihnen bezeichnet, gelten muss h(x) <= d(x,y) +h(y)"
Es genügt also zu zeigen, dass unsere Heuristik zulässig und monoton ist. Für den ersten Punkt (Zulässigkeit) ist zu beachten, dass unsere Heuristik (Summe aller Entfernungen) für jede beliebige Konfiguration schätzt, dass jedes Feld nicht nur durch legale Züge eingeschränkt ist und sich frei auf seine Zielposition zubewegen kann, was eindeutig eine optimistische Schätzung ist, daher ist unsere Heuristik zulässig (oder sie überschätzt niemals, da das Erreichen einer Zielposition immer mindestens so viele Züge wie die Heuristik schätzt).
Die in Worten ausgedrückte Monotonieanforderung lautet: "Die heuristischen Kosten (geschätzte Entfernung zum Zielzustand) eines beliebigen Knotens müssen kleiner oder gleich den Kosten des Übergangs zu einem beliebigen benachbarten Knoten plus den heuristischen Kosten dieses Knotens sein."
Damit soll vor allem die Möglichkeit negativer Zyklen verhindert werden, bei denen der Übergang zu einem nicht verwandten Knoten die Entfernung zum Zielknoten stärker verringert als die Kosten für den tatsächlichen Übergang, was auf eine schlechte Heuristik hindeutet.
Der Nachweis der Monotonie ist in unserem Fall recht einfach. Alle benachbarten Knoten x,y haben d(x,y)=1 nach unserer Definition von d. Wir müssen also zeigen
h(x) <= h(y) + 1
was gleichbedeutend ist mit
h(x) - h(y) <= 1
was gleichbedeutend ist mit
Σ d(x i ) - Σ d(y i ) <= 1
was gleichbedeutend ist mit
Σ d(x i ) - d(y i ) <= 1
Wir wissen durch unsere Definition von neighbor_nodes(x) dass zwei Nachbarknoten x,y höchstens die Position eines Quadrats haben können, was bedeutet, dass in unseren Summen der Term
d(x i ) - d(y i ) = 0
für alle bis auf 1 Wert von i. Nehmen wir ohne Verlust der Allgemeinheit an, dass dies für i=k gilt. Außerdem wissen wir, dass sich der Knoten für i=k höchstens um einen Ort bewegt hat, so dass sein Abstand zu einem Zielzustand höchstens um eins größer sein als im vorherigen Zustand:
Σ d(x i ) - d(y i ) = d(x k ) - d(y k ) <= 1
die Monotonie zeigt. Dies zeigt, was gezeigt werden musste, und beweist somit, dass dieser Algorithmus optimal ist (in einer Big-O-Notation oder asymptotischen Art und Weise).
Beachten Sie, dass ich die Optimalität in Form der Big-O-Notation gezeigt habe, aber es gibt noch viel Spielraum für die Optimierung der Heuristik. Man kann sie noch weiter verfeinern, so dass sie eine genauere Schätzung der tatsächlichen Entfernung zum Zielzustand liefert, jedoch müssen Sie sicher dass die Heuristik immer eine unterschätzt sonst verlieren Sie die Optimalität!
VIELE MONDE SPÄTER BEARBEITEN
Als ich das später noch einmal las, wurde mir klar, dass die Art und Weise, wie ich es geschrieben hatte, die Bedeutung der Optimalität dieses Algorithmus in gewisser Weise verwirrt.
Es gibt zwei verschiedene Bedeutungen von Optimalität, auf die ich hier hinauswollte:
1) Der Algorithmus erzeugt eine optimale Lösung, d. h. die bestmögliche Lösung unter Berücksichtigung der Zielkriterien.
2) Der Algorithmus erweitert von allen möglichen Algorithmen, die dieselbe Heuristik verwenden, die geringste Anzahl von Zustandsknoten.
Der einfachste Weg, um zu verstehen, warum man Zulässigkeit und Monotonie der Heuristik braucht, um 1) zu erhalten, ist, A* als eine Anwendung von Dijkstras Algorithmus für den kürzesten Weg auf einem Graphen zu betrachten, bei dem die Kantengewichte durch die bisher zurückgelegte Knotenentfernung plus die heuristische Entfernung gegeben sind. Ohne diese beiden Eigenschaften hätten wir negative Kanten im Graphen, wodurch negative Zyklen möglich wären und Dijkstras Algorithmus für den kürzesten Weg nicht mehr die richtige Antwort liefern würde! (Konstruieren Sie ein einfaches Beispiel, um sich davon zu überzeugen).
2) ist eigentlich ziemlich verwirrend zu verstehen. Um die Bedeutung dieser Aussage vollständig zu verstehen, gibt es eine Menge von Quantifizierern in dieser Aussage, z. B. wenn man über andere Algorithmen spricht, bezieht man sich auf similar Algorithmen wie A*, die Knoten expandieren und ohne A-priori-Informationen (außer der Heuristik) suchen. Natürlich kann man ein triviales Gegenbeispiel konstruieren, z. B. ein Orakel oder einen Geist, der einem bei jedem Schritt die Antwort sagt. Um diese Aussage besser zu verstehen, empfehle ich die Lektüre des letzten Absatzes im Abschnitt Geschichte über Wikipedia sowie die Überprüfung aller Zitate und Fußnoten in diesem sorgfältig formulierten Satz.
Ich hoffe, dass damit die letzten Unklarheiten unter den potenziellen Lesern beseitigt sind.